

Robots txt, arama motoru botlarına sitende hangi URL’leri tarayıp hangilerini taramaması gerektiğini söyleyen bir yönerge dosyasıdır. Robots.txt doğru kurgulandığında tarama bütçeni (crawl budget) daha verimli kullanır, gereksiz sayfaların indexlenmesini azaltır ve robots txt oluşturma sürecini teknik SEO’nun en kritik kontrol noktalarından biri haline getirir.
Robots.txt Nedir?
Robots txt, sitenin kök dizininde yer alan robots.txt dosyasıdır ve botlara “şu klasöre girme / şu sayfayı tarayabilirsin” gibi talimatlar verir. Bu dosya, sayfaları “indexleme” komutu değil; ağırlıklı olarak tarama (crawl) yönetimi sağlar. Bu yüzden robots txt ile bir URL’i engellersen, Google çoğu durumda o sayfayı tarayamaz ve içerik sinyalini de göremez.
Kısa kritik: Robots txt bir “yasak” değil, bir “kural seti”dir; bazı botlar uymayabilir ama büyük arama motorları genel olarak uyar.
Robots Dosyası Neden Önemlidir?
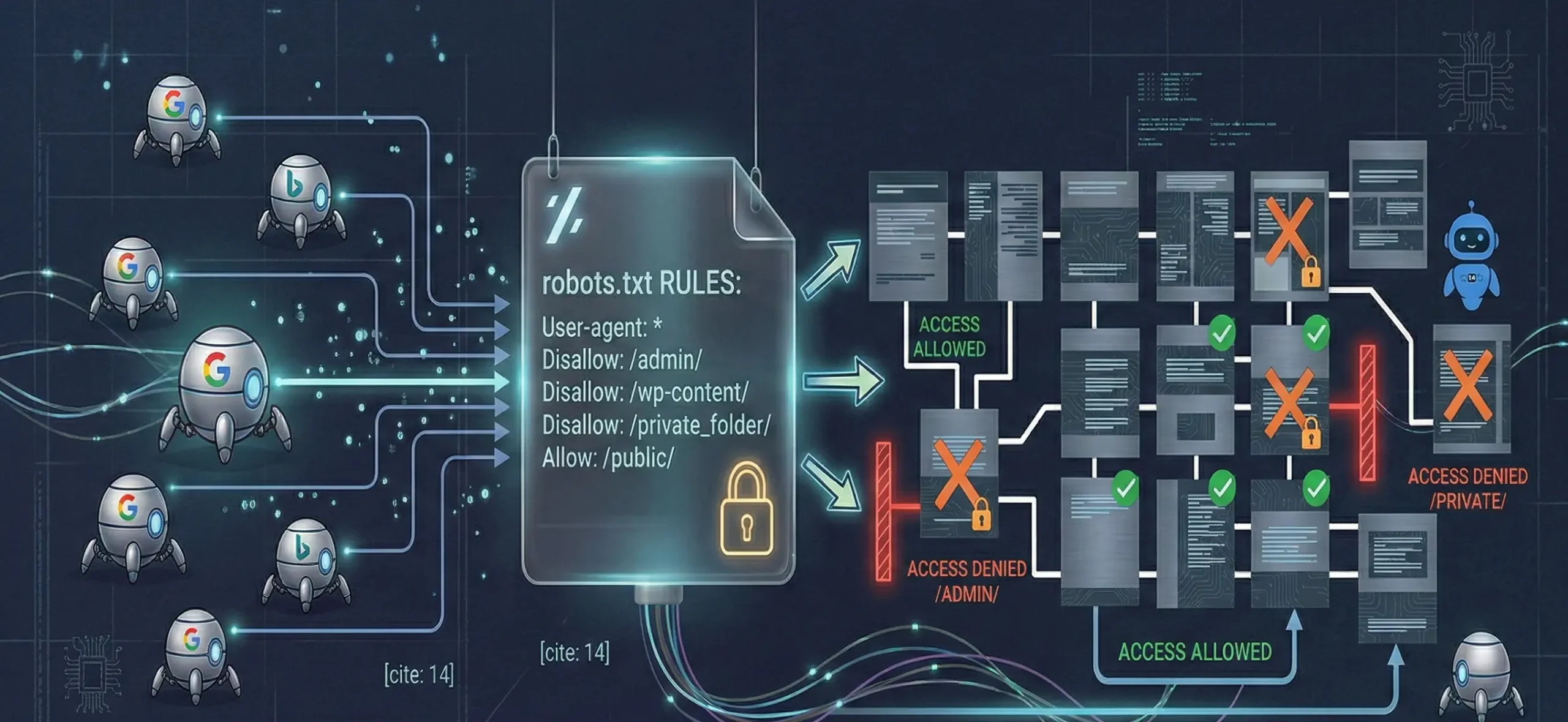
Robots txt dosyası, özellikle büyük sitelerde teknik SEO’nun kontrol paneli gibi çalışır. Robots dosyası neden önemlidir? Çünkü:
- Crawl bütçesini korur: Botun enerjisini gereksiz URL’lere harcamasını engeller.
- Parametreli URL patlamasını yönetir: Filtre/sıralama/utm gibi URL’lerin taranmasını azaltabilir.
- Kritik alanları korur: Admin panelleri, staging ortamları, test dizinleri gibi alanların taranmasını engelleyebilir.
- Sitemap keşfini destekler: Robots içine sitemap satırı ekleyerek botların sitemap’i daha hızlı bulmasını sağlayabilirsin.
- AI bot erişiminde de rol oynar: LLM crawler’ları (siteyi tarayan botlar) için de robots kuralları bazen belirleyici olabilir; ama her botun uyumu aynı değildir.
Robot.txt Oluşturma Nasıl Yapılır?
Robots txt oluşturma, temel mantıkta 3 parçaya dayanır: Hangi bot? Hangi alan? Ne kadar izin? Bunun en güvenli yaklaşımı, minimum kısıt ile başlayıp ihtiyaç oldukça genişletmektir.
Temel örnek (genel kullanım)
User-agent: *
Disallow:
Sitemap: https://site.com/sitemap_index.xml
Bu yapı, tüm botlara tarama izni verir ve sitemap’i belirtir.
Admin ve özel dizinleri kapatma örneği
User-agent: *
Disallow: /wp-admin/
Disallow: /cgi-bin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://site.com/sitemap_index.xml
Robots txt generator ve robots.txt checker kullanımı
- Robots txt generator: Kuralları hızlıca üretmek için kullanılır, ama her site aynı değildir; “hazır şablon” kopyalamak riskli olabilir.
- Robots txt checker: Dosyanın erişilebilir olup olmadığını ve belirli URL’lerin “izinli mi/engelli mi” olduğunu test etmeni sağlar.
Not: Robots txt oluşturma bittikten sonra Google Search Console’daki robots test aracıyla da kontrol etmen iyi olur (özellikle kritik URL’lerde).
WordPress Robots txt Oluşturma
WordPress robots txt oluşturma iki şekilde olur: fiziksel dosya ya da WordPress’in sanal (virtual) robots çıktısı.
1) Fiziksel robots.txt (önerilen kontrol)
- FTP / File Manager üzerinden sitenin kök dizinine robots.txt dosyası eklenir.
- En stabil ve kontrol edilebilir yöntemdir.
2) SEO eklentisi ile (Rank Math / Yoast)
- Bazı eklentiler robots dosyası düzenlemeyi panel üzerinden sağlar.
- Ancak bazı kurulumlarda bu dosya “virtual” çalışabilir; cache/CDN ile çakışma olursa beklediğin güncelleme görünmeyebilir.
WordPress için “en sık yapılan hata”
- wp-content, uploads veya CSS/JS dosyalarını yanlışlıkla engellemek. Bu durumda Google sayfayı doğru render edemez ve kalite sinyali düşebilir.
Sonuç
Robots txt, tarama bütçesini yöneterek organik görünürlükte “temiz sinyal” oluşturmanın en kritik parçalarından biridir. Doğru robots txt oluşturma ile gereksiz URL’leri kısar, önemli sayfalara tarama önceliği verirsin. Eğer sitende indexleme dalgalanıyor, tarama bütçesi boşa gidiyor veya robots.txt checker testlerinde çelişkiler görüyorsan, SEO danışmanlığı ile sitene özel robots stratejisini (sitemap + canonical + internal link uyumuyla) kurup organikte gerçekten harikalar yaratabiliriz.
SSS
Robots txt ile sayfa indexleme nasıl engellenir?
Robots.txt tek başına “kesin index engelleme” aracı değildir; noindex bunun için daha doğru sinyaldir. Robotstxt bir URL’i taramadan (crawl) men eder; Google sayfayı tarayamazsa içeriği göremez, fakat URL başka yerlerden link alıyorsa bazen içerik görülmeden de dizinde görünebilir. “Indexlenmesin” istiyorsan en güvenlisi sayfayı taranabilir bırakıp meta robots: noindex kullanmak; private alanlarda 401/403 ile erişimi kısıtlamak; kalıcı kaldırmada 404/410 veya doğru 301 yönlendirme uygulamaktır.
Robots.txt checker ile test nasıl yapılır?
Robots.txt checker ile belirli bir URL’in robots kurallarına göre “Allowed / Disallowed” olup olmadığını test edersin. Önce site.com/robots.txt dosyasının 200 döndüğünü kontrol et; ardından checker aracında robots içeriğini okut ve test etmek istediğin URL’i gir. Sonuç “Disallowed” çıkarsa kuralın hangi satırdan tetiklendiğini bul. Cache/CDN kullanıyorsan robots dosyası güncellemesi gecikebilir; testin “yayındaki güncel dosya” üzerinden yapıldığından emin ol.
Sitemap robots.txt içine eklenmeli mi?
Evet, önerilir; zorunlu değildir ama botların sitemap’i daha hızlı keşfetmesini destekler. Robots dosyasına sitemap satırı ekleyebilirsin: Sitemap: https://site.com/sitemap_index.xml. Birden fazla sitemap varsa ayrı satırlar halinde eklenebilir. URL’in https ve www/non-www versiyonu sitenin ana versiyonuyla tutarlı olmalıdır.
Robots txt yanlış olursa SEO’ya etkisi ne olur?
Yanlış robots txt organik görünürlüğü doğrudan düşürebilir çünkü botlar önemli sayfalara erişemez. Önemli sayfalar taranamazsa indexleme yavaşlar/düşer; CSS/JS engellenirse render bozulup kalite sinyali düşebilir; parametreli/kopya URL’ler açık kalırsa crawl bütçesi boşa gider; en kritik senaryoda Disallow: / gibi bir kural tüm siteyi engelleyip görünürlüğü sert düşürebilir. Bu yüzden değişiklik sonrası mutlaka robots txt checker ile kritik URL’leri test etmelisin.









