

Robots txt is an instruction file that tells search engine bots which URLs on your site they should crawl and which they should not crawl. When Robots.txt is configured correctly, it uses your crawl budget more efficiently, reduces the indexing of unnecessary pages, and turns the robots txt creation process into one of the most critical control points of technical SEO.
What is Robots.txt?
Robots txt is the robots.txt file located in the root directory of the site and gives bots instructions such as “don’t enter this folder / you can crawl this page.” This file is not an “indexing” command; it mainly provides crawl management. Therefore, if you block a URL with robots txt, Google in most cases cannot crawl that page and cannot see its content signals either.
Short critical note: Robots txt is not a “ban” but a “rule set”; some bots may not comply, but major search engines generally do.
Why Is the Robots File Important?
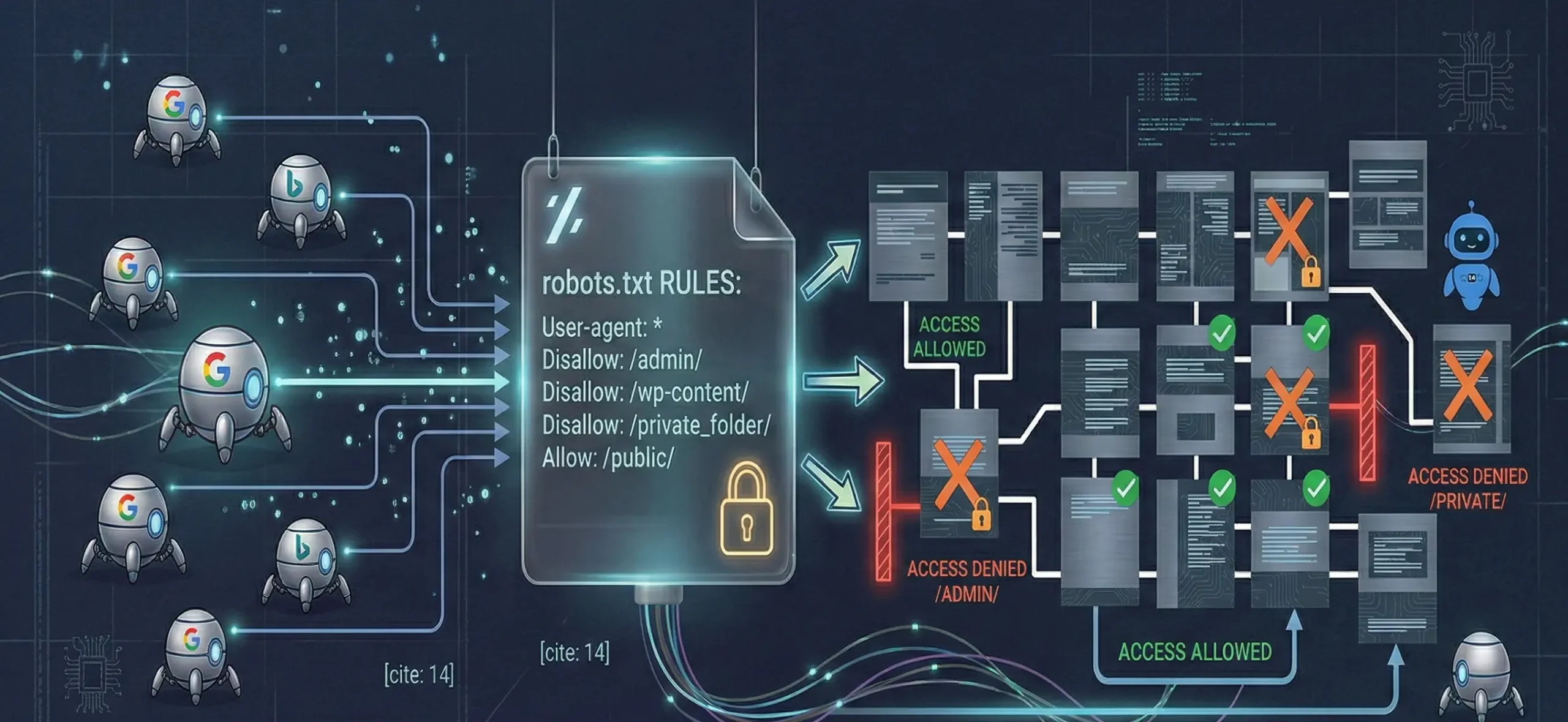
The robots txt file works like a control panel for technical SEO, especially on large sites. Why is the robots file important? Because:
- Protects crawl budget: It prevents the bot from spending its energy on unnecessary URLs.
- Manages parameterized URL explosion: It can reduce crawling of URLs such as filters/sorting/utm.
- Protects critical areas: It can prevent crawling of areas such as admin panels, staging environments, and test directories.
- Supports sitemap discovery: By adding a sitemap line into robots, you can help bots find the sitemap faster.
- Also plays a role in AI bot access: For LLM crawlers (bots that crawl the site), robots rules can sometimes be decisive; but compliance differs for each bot.
How Is Robot.txt Creation Done?
Robots txt creation is based on 3 parts in its basic logic: Which bot? Which area? How much permission? The safest approach is to start with minimal restriction and expand as needed.
1) Basic example (general use)
User-agent: *
Disallow:
Sitemap: https://site.com/sitemap_index.xml
This structure allows crawling for all bots and specifies the sitemap.
2) Example of closing admin and special directories
User-agent: *
Disallow: /wp-admin/
Disallow: /cgi-bin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://site.com/sitemap_index.xml
3) Use of robots txt generator and robots.txt checker
- Robots txt generator: Used to quickly generate rules, but every site is not the same; copying a “ready template” can be risky.
- Robots.txt checker: It allows you to test whether the file is accessible and whether specific URLs are “allowed or blocked.”
Note: After robots txt creation is finished, it is also good to check with the robots test tool in Google Search Console (especially for critical URLs).
WordPress Robots.txt Creation
WordPress robots txt creation happens in two ways: a physical file or WordPress’s virtual robots output.
1) Physical robots.txt (recommended control)
- A robots.txt file is added to the site’s root directory via FTP / File Manager.
- It is the most stable and controllable method.
2) With an SEO plugin (Rank Math / Yoast)
- Some plugins allow editing the robots file through the panel.
- However, in some setups this file may work “virtually”; if it conflicts with cache/CDN, the update you expect may not appear.
“The most common mistake” for WordPress
Accidentally blocking wp-content, uploads, or CSS/JS files. In this case Google cannot render the page properly and the quality signal may drop.
Conclusion
Robots txt is one of the most critical parts of creating a “clean signal” for organic visibility by managing crawl budget. With correct robots txt creation, you reduce unnecessary URLs and give crawling priority to important pages. If indexing is fluctuating on your site, crawl budget is being wasted, or you see conflicts in robots.txt checker tests, with SEO manager we can build a site-specific robots strategy (in alignment with sitemap + canonical + internal links) and truly create wonders in organic.
FAQ
How to prevent page indexing with Robots.txt?
Robots.txt is not a “definitive indexing prevention” tool on its own; noindex is a more accurate signal for this. Robots.txt prevents a URL from being crawled; if Google can’t crawl the page, it can’t see the content, but if the URL has links from elsewhere, it can sometimes appear in the index without the content being seen. If you want “not indexed,” the safest is to keep the page crawlable and use meta robots: noindex; restrict access with 401/403 in private areas; for permanent removal use 404/410 or a correct 301 redirect.
How to test with robots.txt checker?
With robots.txt checker you test whether a specific URL is “Allowed / Disallowed” according to robots rules. First check that the site.com/robots.txt file returns 200; then have the checker tool read the robots.txt content and enter the URL you want to test. If the result is “Disallowed,” find which line triggers the rule. If you use cache/CDN, robots.txt updates can be delayed; make sure the test is based on the “current live file.”
Should sitemap be added into robots.txt?
Yes, it’s recommended; it’s not mandatory but it helps bots discover the sitemap faster. You can add a sitemap line to the robots file: Sitemap: https://site.com/sitemap_index.xml. If there are multiple sitemaps, they can be added as separate lines. The https and www/non-www version of the URL should be consistent with the site’s main version.
What is the SEO impact if robots.txt is wrong?
A wrong robots.txt can directly reduce organic visibility because bots can’t access important pages. If important pages can’t be crawled, indexing slows down/drops; if CSS/JS is blocked, rendering breaks and quality signals may drop; if parameterized/duplicate URLs remain open, crawl budget is wasted; in the most critical scenario, a rule like Disallow: / can block the entire site and sharply reduce visibility. Therefore, after changes you should definitely test critical URLs with robots.txt checker.









